Image Difference Captioning (IDC) using ViT and GPT-2 with Cross Attention
What is IDC?
Image Difference Captioning (IDC) focuses on generating textual descriptions that highlight differences between two images. It goes beyond traditional image captioning, which generates descriptions for a single image, by describing specific changes or differences between two similar images.

To tackle IDC, I began by solving the simpler problem of single-image captioning, planning to extend the solution to dual-image inputs.
Single Image Captioning
Given my prior experience working with Vision Transformer (ViT) and GPT-2, it made sense to combine these models. I used ViT as the image encoder to extract visual features and GPT-2 as the text decoder to generate captions.
Initial Results: Training this framework on the MS COCO dataset revealed that while the model excelled at object detection, it struggled with grammar and identifying relationships between objects.
Improvement: Adding a cross-attention mechanism between the ViT encoder and GPT-2 decoder improved the coherence and contextual accuracy of the generated captions significantly.

Extending to Dual Image Input for IDC
For IDC, I designed a dual-branch network with two ViT encoders—one for each image. Averaging image embeddings was unsuitable for IDC as it emphasizes similarities and not differences. Instead, I concatenated the embeddings and processed them through dense layers to prepare for the GPT-2 decoder.
Challenge: GPU limitations caused Out of Memory (OOM) errors, restricting training to a single epoch, resulting in incoherent outputs.
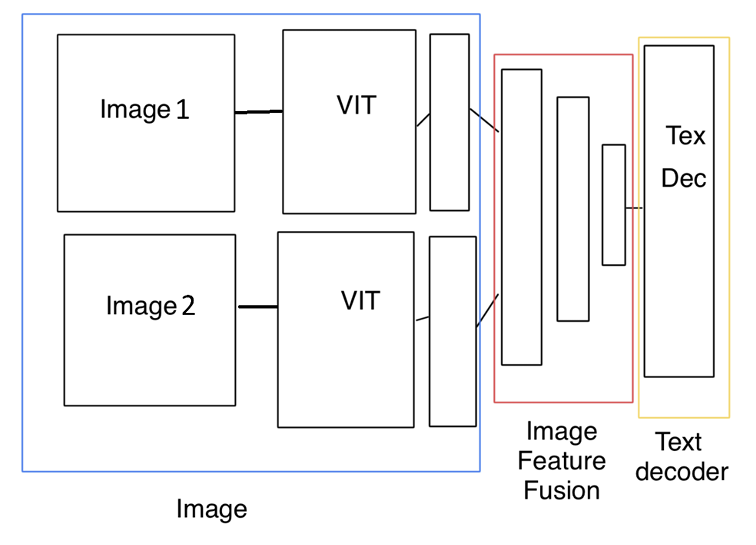
Workaround and Results
To overcome hardware limitations, I horizontally concatenated image pairs with padding to preserve aspect ratios. This approach allowed the single-image captioning model to adapt for IDC.

Performance: The model generated meaningful captions for half the image pairs. However, some outputs were either empty or incoherent.

Conclusion
This project demonstrated the potential of transformer-based models for IDC. It sets a foundation for other problems such as video understanding and anomaly detection.