Reinforcement Learning Project: Optimized Pathfinding in a Grid Environment
Summary
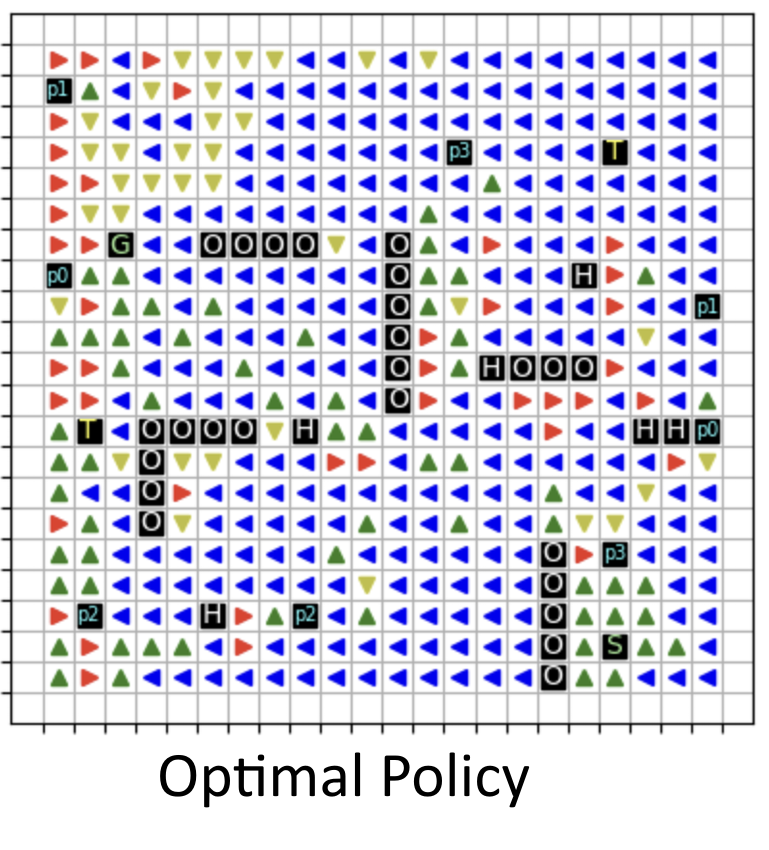
This project was done as part of my reinforcement learning class, where I worked on creating an agent to navigate a 20x20 grid environment filled with challenges. The goal was to reach a designated endpoint while maximizing rewards by collecting treasures, using portals (teleportation portals) to reach the goal quicker, and avoiding penalties from hazards like holes. The problem was to optimize the agent's policy to balance exploration and exploitation effectively.
Algorithm and Approach
I used the Dyna-Q+ algorithm, which combines traditional learning from direct experiences with simulated planning. This made it perfect for the dynamic grid, where treasures disappear after collection and the environment is rich in obstacles. Actions involved moving across the grid, and the states represented the agent's position. To fine-tune the model, I experimented with parameters like gamma (0.8 for valuing future rewards), epsilon (0.1 for exploration), and kappa (0.1 for balancing exploration incentives). These choices allowed the agent to learn efficiently while avoiding overly cautious or inefficient strategies.
Results and Observations
The results were promising, as the agent successfully learned to use teleportation portals and avoid hazards. However, a noted limitation was its suboptimal strategy for consistently collecting treasures. Incorporating a memory-enhanced approach could further improve treasure collection and overall reward accumulation in future iterations. Overall, it was a fun and challenging project that gave me hands-on experience in applying reinforcement learning to a dynamic and multi-faceted environment.