Leveraging Large Multimodal Models for Building Damage Assessment
This project is part of my work at the Computer Vision Lab at UC Merced, under the guidance of Prof. Shawn Newsam, in collaboration with Prof. Henry Burton from UCLA. Our findings were published at GeoAI, ACM SIGSPATIAL '24.
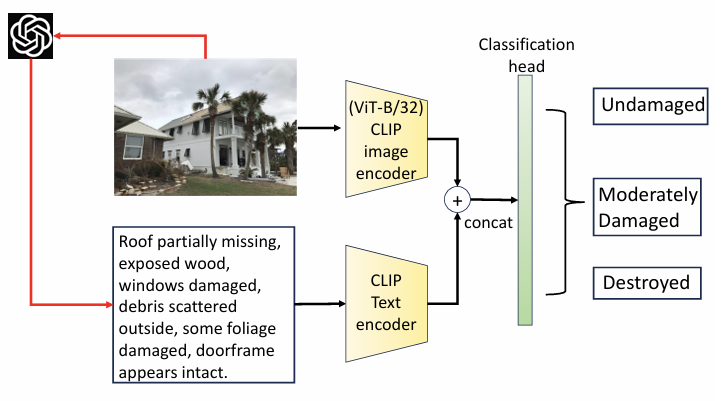
The goal of this project was to automate building damage assessment—determining the level of damage—after natural disasters like hurricanes or earthquakes using AI. Specifically, we explored the question: "Can image descriptions generated by large multimodal models (LMMs) like ChatGPT improve the performance of purely image-based models such as ViT or ResNet?"
The dataset included varying numbers of images per building instance, with at least one external shot and multiple close-up shots of damage. I developed a framework leveraging CLIP to automatically filter relevant external shot images and addressed dataset imbalances through augmentation techniques.
Given the remarkable vision understanding capabilities of LMMs like ChatGPT-4o, I engineered prompts to generate concise, damage-relevant text descriptions from images. I then conducted a comparative study across three approaches: image-only models, text-only models (using GPT-generated text), and vision-language models like CLIP and ViLT.
Our results demonstrated that combining image features with text descriptions significantly enhanced classification performance, confirming that the generated image descriptions are complementary to image-based features.
For more details, check out the full paper here.